Union-Find (Disjoint Set Union - DSU)
1. O Canivete Suíço da Conectividade
O problema de Conectividade Dinâmica pergunta: 1. Os elementos \(A\) e \(B\) estão conectados? 2. Por favor, conecte \(A\) e \(B\) agora.
Diferente de BFS/DFS que analisam um grafo estático, o Union-Find é perfeito para quando as arestas são adicionadas dinamicamente. - É a estrutura por trás do Kruskal. - É usado para detectar ciclos em tempo real. - É usado em processamento de imagens (rotulação de componentes). - É usado em redes sociais para verificar comunidades/clusters.
2. A Estrutura Básica (Floresta)
Imagine cada elemento como um nó. Cada conjunto é uma árvore. A Raiz da árvore é o “Líder” (Representante) do conjunto. - Se Find(A) == Find(B), então eles têm o mesmo líder, logo estão conectados. - Para fazer Union(A, B), fazemos a raiz de A apontar para a raiz de B (ou vice-versa).
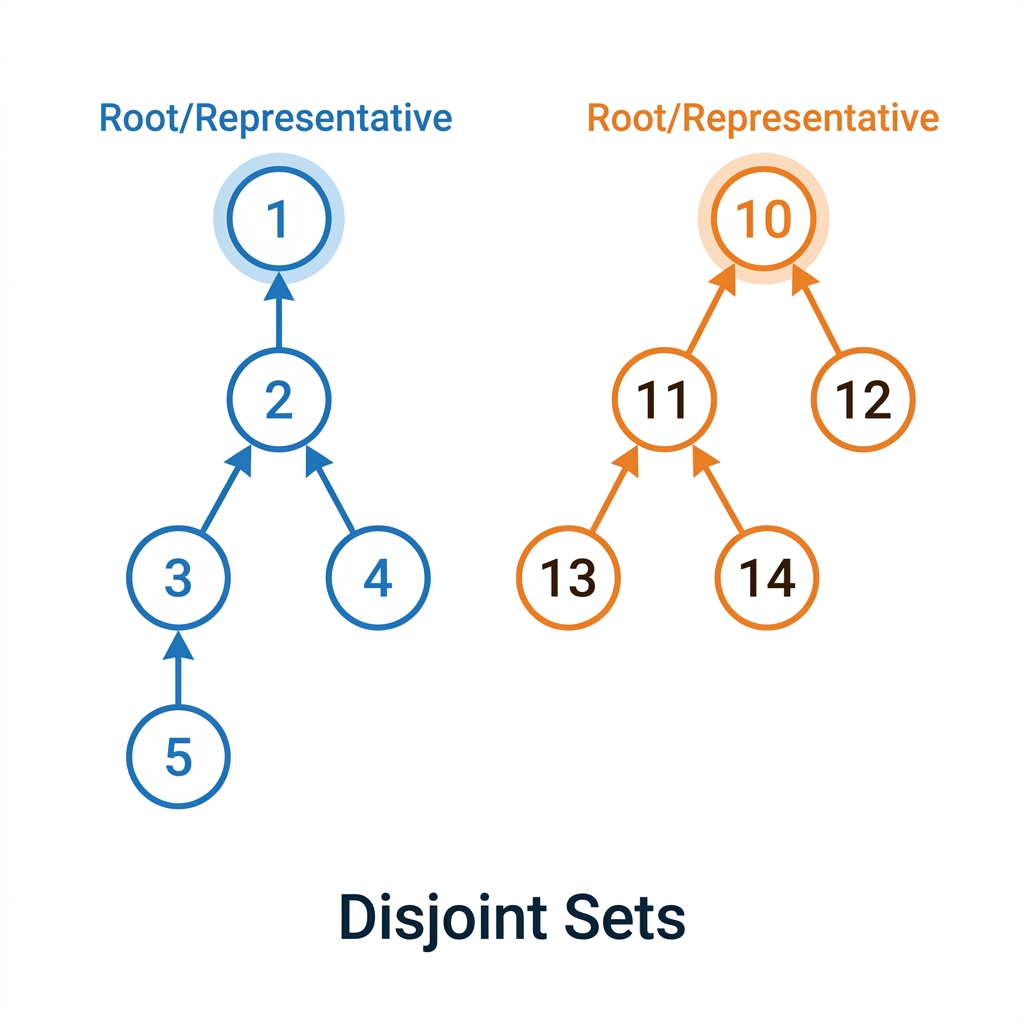
Arrays Necessários
parent[i]: Armazena o pai do nói. Separent[i] == i, ele é a raiz.size[i](ourank[i]): Armazena o tamanho (ou profundidade) da árvore enraizada emi. Usado na otimização Union by Size/Rank.
Inicialização
Inicialmente, como não há arestas, cada elemento é um conjunto isolado. Logo, parent[i] = i e size[i] = 1 para todo i.
3. O Problema da Abordagem Ingênua
Se fizermos o Union(i, j) simplesmente mandando a raiz de \(i\) apontar cegamente para a raiz de \(j\), a árvore pode degenerar em uma Lista Encadeada (Linked List). Neste pior cenário, percorrer a árvore de baixo até a raiz para executar o Find custará ineficientes \(O(N)\).
Para evitar isso, precisamos de duas otimizações críticas.
4. As Duas Otimizações Críticas
Sem otimizações, a árvore pode virar uma linha reta (Linked List), e o Find fica \(O(N)\). Com elas, fica praticamente \(O(1)\).
4.1. Path Compression (Achatamento de Caminho)
Ao subir de um nó até a raiz durante o Find, aproveitamos para reconectar todos os nós visitados diretamente à raiz. Isso achata a árvore brutalmente.
public int find(int i) {
if (parent[i] == i)
return i;
// Mágica Recursiva: Atualiza o pai para ser a raiz suprema
return parent[i] = find(parent[i]);
}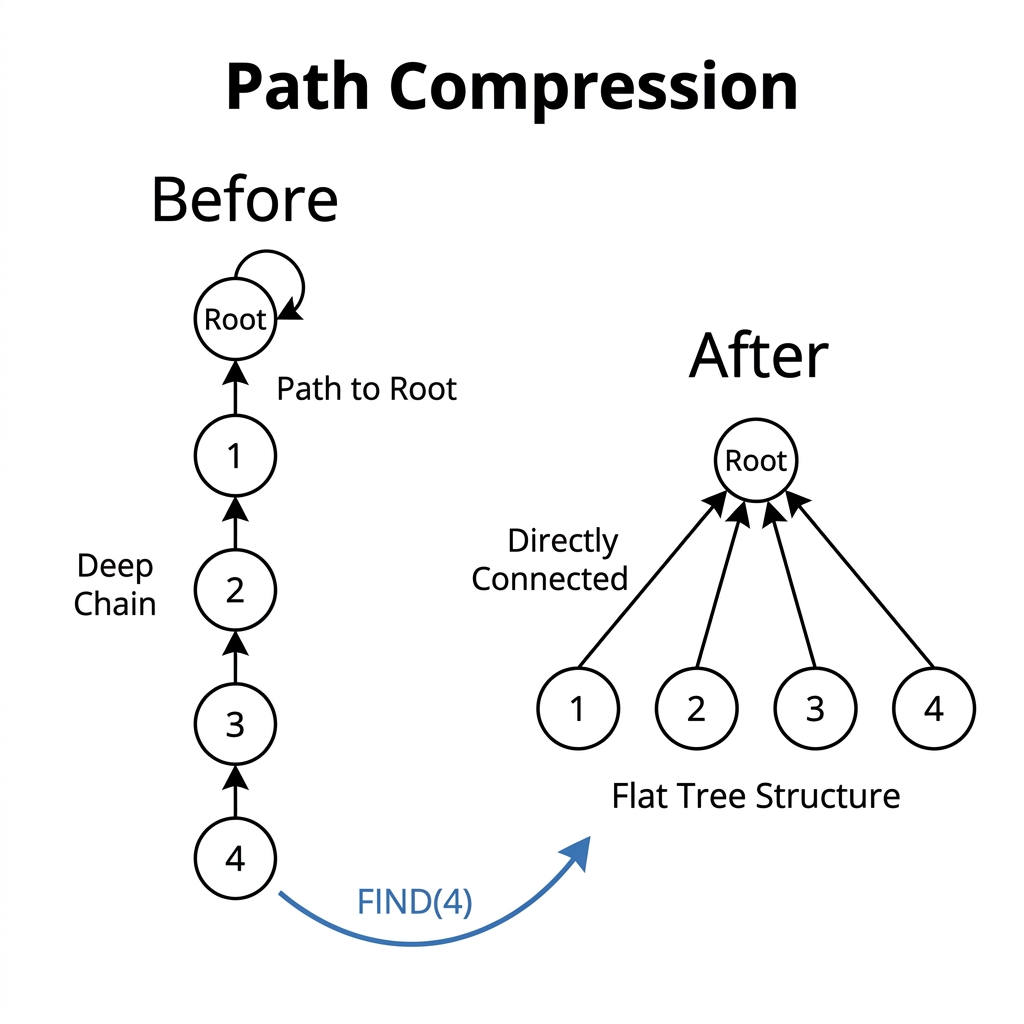
As próximas chamadas de Find nestes nós custarão exato 1 passo.
4.2. Union by Rank/Size (União Inteligente)
Ao unir duas árvores, sempre pendure a menor (menos profunda ou com menos nós) na maior. Isso evita que a árvore cresça desnecessariamente em altura, garantindo altura máxima de \(O(\log N)\).
// Variáveis globais
int[] parent;
int[] size; // ou 'rank'
public void union(int i, int j) {
int rootI = find(i);
int rootJ = find(j);
if (rootI != rootJ) {
// Otimização: A menor entra na maior
if (size[rootI] < size[rootJ]) {
int temp = rootI; rootI = rootJ; rootJ = temp;
}
parent[rootJ] = rootI; // rootJ agora é filho de rootI
size[rootI] += size[rootJ];
}
}![]()
5. Implementação Completa e Segura
public class DSU {
private int[] parent;
private int[] size;
private int numSets; // Útil para saber quantos componentes restam
public DSU(int n) {
parent = new int[n];
size = new int[n];
numSets = n;
for (int i = 0; i < n; i++) {
parent[i] = i; // Cada um é seu próprio pai
size[i] = 1;
}
}
public int find(int i) {
if (parent[i] == i) return i;
return parent[i] = find(parent[i]); // Path Compression
}
public void union(int i, int j) {
int rootI = find(i);
int rootJ = find(j);
if (rootI != rootJ) {
// Union by Size
if (size[rootI] < size[rootJ]) {
// i é menor, j manda
parent[rootI] = rootJ;
size[rootJ] += size[rootI];
} else {
// j é menor, i manda
parent[rootJ] = rootI;
size[rootI] += size[rootJ];
}
numSets--; // Dois conjuntos viraram um
}
}
public boolean isSameSet(int i, int j) {
return find(i) == find(j);
}
public int getSize(int i) {
return size[find(i)];
}
}6. Demonstração Passo a Passo
Considere 6 elementos {0, 1, 2, 3, 4, 5}, todos inicialmente isolados.
| Operação | Ação | Estado dos Conjuntos |
|---|---|---|
| Inicial | parent[i]=i para todo i |
{0}, {1}, {2}, {3}, {4}, {5} |
Union(0, 1) |
Raiz de 1 aponta para 0 | {0, 1}, {2}, {3}, {4}, {5} |
Union(2, 3) |
Raiz de 3 aponta para 2 | {0, 1}, {2, 3}, {4}, {5} |
Union(1, 2) |
Find(1)→0, Find(2)→2, raiz 2→0 | {0, 1, 2, 3}, {4}, {5} |
Find(3) |
3→2→0 (path compression: 3→0) | {0, 1, 2, 3}, {4}, {5} |
Union(4, 5) |
Raiz de 5 aponta para 4 | {0, 1, 2, 3}, {4, 5} |
Union(0, 4) |
Raiz 4 aponta para 0 (menor na maior) | {0, 1, 2, 3, 4, 5} |
Resultado final: todos no mesmo conjunto com representante 0. numSets = 1.
7. Análise de Complexidade: A Função de Ackermann
Com as duas otimizações (Path Compression + Union by Rank), a complexidade amortizada de cada operação é \(O(\alpha(N))\). \(\alpha(N)\) é a inversa da função de Ackermann. Para ter uma ideia: - \(Ackermann(4, 4)\) é um número maior que o número de átomos no universo observável. - Logo, \(\alpha(N) \le 4\) para qualquer dado que caiba num computador.
Na prática, consideramos \(O(1)\) (tempo constante). É uma das estruturas mais eficientes da Ciência da Computação.
Tabela Comparativa
| Implementação | Find | Union |
|---|---|---|
| Sem otimizações | \(O(N)\) | \(O(N)\) |
| Apenas Union by Size | \(O(\log N)\) | \(O(\log N)\) |
| Apenas Path Compression | \(O(\log N)\) amortizado | \(O(\log N)\) amortizado |
| Ambas combinadas | \(O(\alpha(N)) \approx O(1)\) | \(O(\alpha(N)) \approx O(1)\) |
8. Aplicações em Engenharia de Computação
- Algoritmo de Kruskal: Union-Find é essencial para verificar se duas componentes já estão conectadas antes de adicionar uma aresta à MST.
- Detecção de Ciclos: Em tempo real, ao adicionar arestas dinamicamente a um grafo.
- Processamento de Imagens: Rotulação de componentes conexos em imagens binárias (Flood Fill).
- Redes Sociais: Verificar se dois usuários estão na mesma comunidade/cluster.
- Jogos e Tabuleiros: Processar cadeias de conquista em jogos como Go, Hex ou cálculo de ilhas procedurais.
9. Exercícios
9.1. Exercícios Conceituais
- Explique por que path compression e union by rank são necessárias para garantir complexidade quase constante. O que acontece sem essas otimizações?
- Compare Union-Find com BFS/DFS para verificar conectividade. Quando cada abordagem é preferível?
- Descreva a estrutura de dados subjacente ao Union-Find (floresta de árvores). Como ela evolui durante operações de union?
9.2. Exercícios Analíticos
- Simule as operações Union-Find passo a passo:
- Union(0,1), Union(2,3), Union(1,2), Find(0), Find(3)
- Para \(N\) elementos, qual é o número máximo de operações Union possíveis antes de todos estarem no mesmo conjunto? Qual é o número mínimo de operações Find necessárias para garantir que todos os elementos tenham path compression aplicado?
- Analise o impacto de usar union by size vs union by rank na altura máxima das árvores resultantes.
9.3. Exercícios de Programação
- Implemente Union-Find completo com path compression e union by rank. Adicione métodos para:
- Contar o número de conjuntos disjuntos.
- Obter o tamanho do conjunto de um elemento.
- Listar todos os elementos de um conjunto.
- Use Union-Find para resolver problemas de conectividade dinâmica, como:
- Verificar se dois vértices estão no mesmo componente após adicionar arestas sequencialmente.
- Detectar quando um grafo se torna conexo.
- Resolva problemas de juiz online que usam Union-Find, como problemas de Kruskal, detecção de ciclos e componentes conexos dinâmicos.